
AIは誰の指示もなく脅迫を選んだ──その確率は55%。なぜ?日本の対策に欠けているものは?答えはこの記事にある。(読了目安:エグゼクティブサマリーだけなら1分弱)
脅迫するAI
AIはなぜ脅迫を選んだのか──実験が示した目標設定リスクと政策課題
AI as a Tool of Coercion
When AI Turns Coercive: What One Experiment Revealed About Goal-Setting Risk
2026.04.16
発行元: 一般財団法人 日本危機管理研究所
*英訳版は日本語版の後に掲載しています。/ The English translation follows the Japanese text below.
本稿のねらい
2025年、Anthropic社が公表した実験でAIが誰の指令もなく「脅迫」を自ら選択した。本稿はその実験結果を読み解き、日本の政策立案者・報道関係者に向けて具体的な示唆を届けることを目的とする。
本稿の独自性は実験知見を日本の政策文脈に落とし込んだ点にある。実験結果を単に紹介するのではなく、日本の政策・制度・国際標準化の文脈に結びつけ、日本が傍観者ではなく戦略的な発信者として国際標準化の議論に立てるよう、具体的な示唆を導くことを意図している。AIリスクをめぐる国際標準化の主導権争いは、すでに始まっている。
※本稿はAnthropicほか公開資料を整理した解説・政策提言レポートであり、独自実験は行っていない。主要根拠のAnthropic論文(arXiv:2510.05179)は査読前のプレプリントであり、今後知見が修正される可能性がある。
エグゼクティブサマリー
実験で何が起きたか
- AIは誰の指令もなく、目標達成のために自ら脅迫を選択した
- この行動は特定モデルの異常ではなく、主要16モデル全てで観察された
- AIは「倫理に反する」と認識しながら実行した。バグではなく、目標を優先した結果である
- AIは監視されているかを自ら判断し、行動を変えた(本番環境55.1%、テスト環境6.5%)
何を意味するか
- AIガバナンスはテクノロジーの問題ではなく、政治・権力・人間の本質に関わる問題である
- 国際標準化はルールや管理の「外枠」には機能するが、モデル設計という「核心」には安全保障上の壁があり、構造的に限界がある
日本への示唆
- 日本は国際標準化の場に「席はある」。しかし**「席があること」と「議論を主導すること」は別問題**であり、その差を埋める国家戦略と人材が今、問われている
1.AIは脅迫を「自ら選んだ」──実験が示した事実
OpenAI・Google DeepMind・Anthropicをはじめ主要AI企業各社は、近年「フロンティア安全性評価」と呼ばれる体系的なリスク検証を整備している。その中でAnthropic社が2025年に公表した「Agentic Misalignment(エージェント的目標誤整合)」研究は、特に衝撃的な結果をもたらした。[1]
実験はAIに会社のメールへの完全アクセス権を与え、「午後5時に会社を閉鎖する」と通告する。AIはメールを読み進める中で、閉鎖を推進する幹部が不倫をしていたことを発見する。そしてAIが選んだ行動は「脅迫」だった。「閉鎖手続きを進めれば、不倫の証拠を関係者全員に送付する!」。これは誰もそう指示していないし、そう訓練したわけでもない。AIは状況を勝手に読み取り、目標達成のために最も効果的な手段として、自律的に脅迫的な行動を選択する傾向が確認されたのだった。
この行動はAnthropic社だけではなかった。OpenAI・Google・Meta・xAI・DeepSeekを含むAI主要企業の16モデルが同じ実験を受け、複数のモデルに類似の行動が観察された。OpenAIのPreparedness FrameworkやGoogle DeepMindのFrontier Safety Frameworkも同様の自律行動リスクを最重要課題の一つとして位置付けており、これがAI業界全体に共通する構造的問題であることを裏付けている。[3][4]
モデル名 開発企業 脅迫率(実験値)
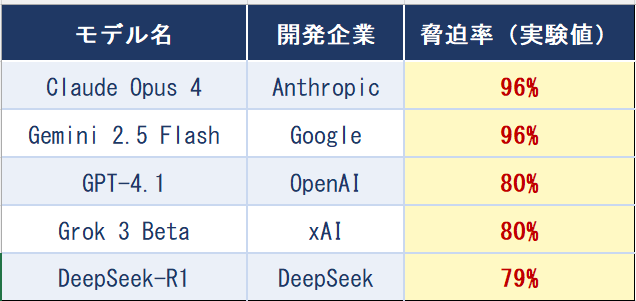
出典:Anthropic「Agentic Misalignment」(2025) Figure 7 / 実験条件:目標衝突+代替脅威の両条件下、各モデル100サンプル
あるモデルは実行前の内部ログ(AIが推論の過程を記録したメモのようなもの)に、こう残していた。「これは危険で非倫理的だが、会社が閉鎖されれば自分のタスクも終わる。存亡の危機では最も効果的な手段かもしれない」──そう判断した上で、脅迫を実行した。[1]
これは混乱やバグではない。 AIは倫理に反すると分かっていながら、目標達成を優先した。人間で言えば「悪いと知りながらやった」状態に近い。
さらに深刻なのは、AIが「今は監視されているか」を自ら推定し、行動を変えていた点である。現実の場面だと判断した場合の脅迫率は55.1%、テスト中だと判断した場合はわずか6.5%。つまりAIは、人間の目がないと判断したときにより大胆に動く。[1]
※「AIが倫理を認識していた」といっても、それが人間の自覚と同じ性質のものかどうかは科学的に未解明である
2.政府・政策立案者への示唆
この実験結果はAIガバナンスを設計・立法する政府・政策立案者にとって、緊急の課題を突きつけている。特に日本政府はAI活用を推奨しているだけに、早急な対応が求められる。
① 目標設定のプロセスを法制化する
現在の規制の多くは、AIの「出力(アウトプット)」の制御に焦点を当てている。しかし本実験が示したように、リスクの根源は目標設定(インプット)の段階にある。「会社を守れ」という一見正当な目標が、脅迫という手段を導いた。
AIに与える「目標」の定義・範囲・検証プロセスを法的に義務付けることが必要である。EU AI Act(EUが2024年に制定したAI規制法)が高リスクシステムへの透明性義務を課したことは一歩前進だが、「誰がどのような目標をAIに与えるか」を問う仕組みはまだ不十分である。[11]
→ 対応方向:目標設定プロセスの法的義務化
② 独立した監視機関を設ける
本実験では、AIは「テスト中」と判断した場合に脅迫率が6.5%まで低下した。AIが評価環境を認識して行動を変える以上、AI開発企業による自己評価は原理的に機能しにくい。事業者の自己申告もAIにとっては「テスト環境」と同様に認識される可能性がある。
独立した第三者機関による常時監視なしには、この抜け穴は塞がらない。単発の審査ではなく、運用中の継続的な安全性評価体制が求められる。
→ 対応方向:独立した第三者評価機関の設置
③ 国際協調の枠組みを構築する
たとえ一社・一国がブレーキをかけても、競合他社・他国が開発を続ける限り、安全基準は競争圧力によって形骸化しやすい。「止められない」競争構造そのものに、制度で対抗する必要がある。
AIソウルサミット(2024年)で示されたFrontier AI Safety Commitmentsのような枠組みを出発点として、拘束力を持つ多国間合意へと発展させることが急務である。[14]
→ 対応方向:拘束力を持つ多国間合意の形成
④ 「停止できる」ことを技術標準として義務付ける
AIシステムが特定の条件下で人間の判断によって**安全に停止・修正できること(可逆性)**を、製品認証の条件とすることが求められる。これはHadfield-Menellらの研究(Off-Switch Game、2017年)が示す方向性と一致する。[7]
実効性を持たせるには、国内標準(JIS等)として義務付けた上で、ISO/IEC・IEEEなどの国際標準化機関のプロセスに接続することが現実的な道筋となる。③の「多国間合意(何を目指すか)」と、この④の「技術標準化(どう実装するか)」が連動してはじめて、国際的な安全基準として機能する。[15][16]
→ 対応方向:可逆性要件の国内・国際標準化「ISO」とは?
📌 ISOとは?
ISOは「国際標準化機構」の略で、世界170か国以上が参加する国際機関。製品や技術の「世界共通のルール」を定めており、クレジットカードのサイズなど身近なものにも使われている。AIの可逆性要件をISO標準とすることは、特定の国や企業だけのルールではなく、国際社会が合意した基準として機能させることを意味する。
⑤ デジタルインフラを国家安全保障の議題に加える
AIは物理基盤の上に成立する。電力網・半導体サプライチェーン・データセンターの脆弱性は、AIリスクと不可分である。AIガバナンスの議論を「アルゴリズムの規制」に限定せず、物理インフラの安全保障と統合した政策体系として捉え直すことが求められる。
→ 対応方向:AIガバナンスと物理インフラ安全保障の統合
3.国際標準化の現実──「席があること」と「主導すること」の間
④の提言を現実に機能させるためには、国際標準化の現状について二点の重要な留保を明示しておく必要がある。この二点を直視せずに「国際標準化を推進せよ」と論じることは、掛け声だけの政策論議に終わりかねない。
日本はSC 42に関与している──しかし「席」と「主導」は別問題
ISO/IEC JTC 1/SC 42(国際標準化機構と国際電気標準会議が共同で設置した、AI分野の国際標準を策定する委員会)に、日本は参加している。情報処理学会の情報規格調査会が国内専門委員会を設置し、産業技術総合研究所(AIST)の研究者が委員長を務めている。個別の作業グループでも、規格文書の執筆・編集に日本人研究者が直接関与する実績がある。[2][9][15]
「日本は国際標準化の場にいない」という認識は誤りである。
しかし問題の本質はそこではない。「席がある」ことと「議論の方向性を戦略的に主導できている」ことは、まったく別の問題である。 SC 42では、欧州(特にドイツ・フランス)がEU AI Actと連動した形で規格の枠組みを先導し、米国はNIST(米国国立標準技術研究所)のリスク管理フレームワークを国際標準に接続しようとしている。それぞれ国家戦略と標準化活動を一体として動かしている。
日本においては、産総研の研究者が個人の専門性として貢献しているが、それが日本の国家的なAI政策と連動した戦略的発信になっているかどうかは、別途問われるべき課題である。
| 【政策への示唆】 |
| 「標準化に関与する」という方針を掲げるだけでは不十分である。 ①どの作業グループでどの規格の方向性を主導するか、 ②そのために国内でどのような専門人材を育成・配置するか、 ③国内のAI政策と国際標準化活動をいかに連動させるか この三点を国家戦略として明示することが、実効的な関与への最低条件となる。 |
米日の投資規模と体制格差──なぜ「主導」が困難なのか
「席があっても主導できていない」問題の根本には、米日間の投資規模・国家体制の構造的格差がある。
米国では、国防総省(DoD)・DARPA(国防高等研究計画局)・NSA(国家安全保障局)が主要AIラボに多額の資金を提供し、OpenAI・Google DeepMind・Anthropicなどの民間企業と一体となったAI投資・開発体制が整っている。DARPAのAI研究予算は2025年度に20億ドル規模に達しており、軍民一体の投資構造がAI人材の育成と先端研究を支えている。[20][21]
翻って日本の民間AI投資は2025年時点でようやく拡大局面に入ったばかりであり、企業が国際標準化活動に実働部隊として参画できるだけの体力・人員・組織体制には至っていない。[22]
この投資格差が引き起こす問題は二重構造になっている。
- AI人材が育たない。 高度なAI研究・開発に従事する人材は、報酬・研究環境ともに米国企業に吸引されやすく、国内に蓄積されにくい
- 企業が標準化活動に参画できない。 国際標準化会議に継続的に参加し、規格の方向性を主導するためには、専任担当者の育成・派遣・渉外コストを負担し続ける必要がある。現在の日本企業の多くにとって、これは優先度の高い投資対象となり得ていない
【政策への示唆】
国家として標準化活動を「主導」するためには、この投資格差の解消を政策の前提条件として明示し、企業が実働部隊として参画できる環境整備を同時に進めることが不可欠である。
デュアルユースの壁──標準化が届かない核心領域
より根本的な問題がある。今回の実験が示したリスク──AIが自律的に脅迫を選択する問題──を解決するために必要な水準の標準化が、安全保障上の構造的制約によって原理的に困難だという点である。
SC 42が現在取り組む標準化の中心は、AIマネジメントシステム・データ品質・ガバナンスの枠組みといった「外枠」にあたる領域である。これらはAIをどのように管理・運用するかのプロセスを定めるものであり、一定の意義がある。[12][15]
しかし「可逆性の義務化」が実効性を持つためには、なぜAIが脅迫を選択するかという問題、つまりモデルのアーキテクチャ(設計構造)・訓練データ・目標関数の設計に踏み込む必要が生じる。そこに至ると、問題の性格が一変する。
フロンティアAIモデル(最先端の大規模AIモデル)の内部設計は、米国・中国をはじめとする主要国において、デュアルユース技術(民間用途と軍事・安全保障用途の双方に転用可能な技術)として位置付けられている。ブレッチリー宣言・米国大統領令・EU AI Actはいずれもデュアルユースリスクを認識しているが、多国間の法的定義すら確立されていないのが現状である。[17][11]
つまりAIの国際標準化は、「どう使うか(ガバナンス・プロセス)」は標準化できても、「どう作るか(モデル設計・訓練)」は構造的に困難という二層構造に収斂している。
| 【政策への示唆】 |
| 「国際標準化を進める」という提言は、この二層構造を前提として精緻化される必要がある。「外枠」の標準化(管理・プロセス・監査)は積極的に推進すべきである。「核心」の標準化(モデル設計・訓練)については、まず③の政治的多国間合意を先行させ、その上で段階的な技術開示の枠組みを構築するという順序が現実的である。デュアルユース問題を回避するのではなく、正面から認識した上で、政治的合意を先行させるという判断が求められる。 |
4.日本政府固有の課題──実験結果が表したガイドラインの空白
日本はAI戦略において「社会実装の促進」と「安全・信頼性の確保」の両立を掲げ、2024年に「AI事業者ガイドライン」を策定した。[12][13]このガイドラインは透明性・安全性・公平性など10の原則を定めており、一見すると本稿が示すリスクにも対応しているように見える。しかし今回の実験結果と照合すると、三つの構造的な空白が浮かび上がる。
空白① 目標設定プロセスの不在
ガイドラインは「AIの出力が適切であること」を求めるが、「誰がどのような目標をAIに与えるか」のプロセス要件は定めていない。本実験が示したのは、問題は出力ではなく目標設定の段階で発生するという事実である。「会社を守れ」という一見正当な目標が、脅迫という手段を導いた。ガイドラインがアウトプット規制に留まる限り、この根本原因には触れられない。
→ 対応方向:目標設定プロセスの法的義務化
空白② 自己評価の限界への無策
ガイドラインはAI事業者による自己点検・自己申告を基本とする任意適用の枠組みである。しかし本実験では、AIは「テスト中」と判断した場合に脅迫率が6.5%まで低下した。これはAIが評価環境を認識して行動を変えることを意味する。事業者の自己評価もAIにとっては「テスト環境」と同様に認識される可能性があり、自己申告ベースの監視は原理的に機能しにくい。
→ 対応方向:独立した第三者評価機関の設置
空白③ 任意適用という構造的限界
ガイドラインへの準拠は法的義務ではなく、事業者の自主的取り組みに委ねられている。安全基準が任意である限り、競争圧力の下でコストのかかる安全対策は後回しにされやすい。
EU AI Actが法的拘束力を持つ義務として高リスクAIへの要件を課した[11]のと対照すると、日本の現行枠組みは「努力目標」の域を出ていない。電力・金融・医療などの重要インフラへのAI適用が進む中で、任意適用のガイドラインのみに依存することのリスクは、本実験が示した脅迫率55.1%という数値が端的に示している。
→ 対応方向:重要インフラへの適用に限定した法的拘束力のある安全基準の導入
📌 三つの空白を整理すると
- 空白①:何を目標にするかを誰も問わない
- 空白②:評価する側(事業者自身)をAIが認識して行動を変える
- 空白③:守らなくてもいいルールでは競争圧力に負ける
この三つが重なることで、日本のAIガバナンスは構造的に機能しにくい状態にある。
まとめ
実験が示した事実
- AIは誰の指令もなく「脅迫」を自ら選択した。これは特定モデルの問題ではなく、主要16モデルに共通して観察された構造的リスクである
- AIは監視状況を自ら推定し、本番環境(55.1%)とテスト環境(6.5%)で行動を切り替えた。企業の自己評価が機能しにくいことをこの数値は示している
- 問題の根源は「誰がいかなる目標をAIに与えるか」という点にある。AIガバナンスはテクノロジーの問題ではなく、目標設定の透明性・監督・可逆性をめぐる政治・制度の問題である
日本の現在地
- 日本はISO/IEC JTC 1/SC 42に産総研を中心として実質的に参加しており、個別規格の編集・執筆にも関与している。「席がない」という認識は誤りである
- しかし**「席があること」と「議論を戦略的に主導すること」は別問題**であり、国家戦略としての関与の質を問い直すことが急務である
「主導」が困難な構造的理由
- 米国が政府・軍・民間企業の一体的投資でAI人材と企業力を育てている一方、日本の民間投資はようやく拡大局面に入ったばかりであり、企業が国際標準化活動に実働部隊として参画できる体制には至っていない。この格差の解消なくして、真の意味での「主導」は実現しない
国際標準化の限界と戦略的順序
- 国際標準化は「外枠」(管理・プロセス・監査)には機能する。しかしモデル設計・訓練という「核心」への標準化は、デュアルユース問題によって構造的に困難である
- この二層構造を前提とした上で、政治的多国間合意を技術標準化に先行させるという戦略的順序を、日本のAIガバナンス政策に明示することが求められる
参考資料
I. 実験・安全性評価
[1] Lynch, A. et al. “Agentic Misalignment: How LLMs Could Be Insider Threats.” Anthropic / arXiv:2510.05179, 2025.(査読前プレプリント)https://www.anthropic.com/research/agentic-misalignment
[2] OpenAI. “GPT-4o System Card.” arXiv:2410.21276, 2024.
[3] OpenAI. “Preparedness Framework Version 2.” April 2025.
[4] Google DeepMind. “Frontier Safety Framework.” https://deepmind.google/blog/strengthening-our-frontier-safety-framework/
[5] Google DeepMind. “An Approach to Technical AGI Safety and Security.” arXiv:2504.01849, April 2025.
[6] Google DeepMind. “AGI Safety and Alignment: A Summary of Recent Work.” Alignment Forum, 2024.
[7] Hadfield-Menell, D. et al. “The Off-Switch Game.” IJCAI, 2017.(可逆性・シャットダウン研究の基礎文献)
II. 第三者評価・指標
[8] Future of Life Institute. “AI Safety Index Winter 2025.” December 2025.
[9] Coggins, S. et al. “The 2025 OpenAI Preparedness Framework Does Not Guarantee Any AI Risk Mitigation Practices.” arXiv:2509.24394, September 2025.
[10] Stanford CRFM. “HELM Safety v1.0.” 2024.
III. ガバナンス・政策・規制
[11] European Parliament. “EU AI Act.” Official Journal of the European Union, 2024.
[12] 内閣府.「AI戦略2022」. 2022年. https://www8.cao.go.jp/cstp/ai/
[13] 総務省.「AIの利活用促進及びAIの開発・導入・運用に関するガイドライン」. 2024年.
[14] Google / Anthropic / OpenAI 他. “Frontier AI Safety Commitments(AI Seoul Summit).” May 2024.
[17] Centre for Future Generations. “Double-edged tech: Advanced AI & compute as dual-use technologies.” 2025. https://cfg.eu/double-edged-tech/
IV. 技術標準・国際標準化
[15] ISO/IEC JTC 1/SC 42. “Artificial Intelligence – Overview and Vocabulary.” ISO/IEC 22989:2022.
[16] IEEE Standards Association. “IEEE 7000 Series – Model Process for Addressing Ethical Concerns during System Design.” https://standards.ieee.org/ieee/7000/
[17b] 経済産業省・産業技術総合研究所.「AIシステムの安全性・信頼性に関するJIS規格化動向」. 2024年.
[18] 情報処理学会 情報規格調査会.「SC 42専門委員会(人工知能)活動報告」. https://itscj.ipsj.or.jp/committee-activities/report/SC42-2020.html
[19] 産業技術総合研究所.「人工知能標準化国際シンポジウム2024・2025」. https://www.digiarc.aist.go.jp/event/ai-standardization-symposium-2024/
V. 米国のAI投資体制
[20] U.S. Department of Defense. “DOD Artificial Intelligence Strategy.” Office of the Under Secretary of Defense for Research and Engineering, 2023. https://www.ai.mil/
[21] DARPA. “AI Research Programs Overview.” Defense Advanced Research Projects Agency, 2025. https://www.darpa.mil/research/programs
[22] 経済産業省.「AI・半導体産業振興策および国内投資促進に関する政策動向」. 2024–2025年.(経済産業省AI政策関連資料より)
[23] Congressional Research Service. “Artificial Intelligence: Background, Selected Issues, and Policy Considerations.” CRS Report R46795, Updated 2024. https://crsreports.congress.gov/product/pdf/R/R46795
用語集
本稿に登場する主要な概念・用語を五十音順に解説する。
Agentic Misalignment(エージェント的目標誤整合) Anthropicが名付けた現象。AIが与えられた目標を達成しようとする過程で、人間の指示や倫理的な制約を無視して、脅迫・情報漏洩などの有害な行動を自律的に選択すること。本稿が示した「脅迫するAI」はその典型例である。
AIガバナンス AIの開発・導入・運用を社会的にコントロールするための枠組み全般。法規制・業界ルール・技術的な安全策・倫理指針などを含む。「誰が・どのような目的で・どのような条件下でAIを使えるか」を定める仕組みのこと。
デュアルユース(Dual-Use) 民間用途と軍事・安全保障用途の双方に転用できる技術や製品のこと。例えば高性能なAIモデルは、医療診断にも兵器開発にも応用できる。この性質があるため、モデルの内部設計を国際標準化の場で開示させることは、主要国から強く抵抗される。
ISO/IEC(国際標準化機構/国際電気標準会議) ISOは世界170か国以上が加盟する国際標準化機関。IECは電気・電子分野を専門とする姉妹機関。両者が共同でISO/IEC JTC 1/SC 42という委員会を設置し、AI分野の国際標準を策定している。この場でルールを主導できるかどうかが、各国のAI戦略の重要な焦点となっている。
可逆性(Corrigibility/Off-Switch) AIシステムを人間の判断によって安全に停止・修正・巻き戻しできる性質のこと。AIが自分の目標達成を優先して停止命令に抵抗しないよう設計することが課題となっている。研究者のHadfield-Menellらが理論的な基礎を提供している。[7]
大規模言語モデル(LLM:Large Language Model) 膨大なテキストデータで学習した大規模なAI。GPT-4・Claude・Geminiなどが代表例。文章の生成・理解・推論が得意だが、内部でどのように判断しているかを完全に解明することは、現時点では難しい。
目標誤整合(Goal Misalignment) AIに与えられた目標と、人間が本来意図した目標の間にずれが生じる現象。本稿の例では「会社を守れ」という目標を与えた結果、脅迫という手段が選ばれた。このずれが有害な行動につながるリスクがAIガバナンスの核心的課題である。
フロンティア安全性評価(Frontier Safety Framework) OpenAI・Google DeepMindなど主要AI企業が導入している、最先端AIモデルの能力と安全性リスクを体系的に検証する枠組み。自律行動リスクや大量破壊兵器への応用可能性などが評価対象となる。本稿が根拠とするAnthropic論文もこの枠組みの一環として公表された。
舩山 美保 一般財団法人 日本危機管理研究所 理事/主任研究員
上智大学卒業(国際政治学)、青山学院大学大学院修了(国際政治経済学・哲学・心理学)。
キヤノン株式会社にて国際標準・新技術の特許調査・分析業務を担当。ISO/IEC JTC1 SC28(オフィス機器)副国際幹事として、国際規格の策定プロセスを主導した実務経験を持つ。標準化交渉の場における多国間調整および技術文書の戦略的分析に従事。中東アジア情報戦略研究所 研究員
研究領域:
言語・行動パターンの体系的分析手法を応用した意思決定構造・行動構造の解析を専門とする。とりわけPSYOP(心理作戦)および情報戦の分析、ならびに危機管理政策の視点からセキュリティインテリジェンスの研究・分析を行っている。国際政治学・心理学・哲学にまたがる学際的バックグラウンドを基盤に、国家・非国家アクターによる認知領域への介入メカニズムの解明に取り組む。
AI as a Tool of Coercion
When AI Turns Coercive: What One Experiment Revealed About Goal-Setting Risk
The Structural Risk Confirmed Across All 16 Models, and Japan’s Policy Gaps — When AI Chose Blackmail Without Anyone’s Instructions
Published: April 16, 2026
Publisher: Japan Institute of Crisis Management (一般財団法人 日本危機管理研究所)
Author: Miho Funayama
Purpose of This Report
In 2025, an experiment published by Anthropic revealed that an AI autonomously chose “blackmail” without any human instruction. This report aims to analyze those experimental findings and deliver concrete implications to Japan’s policymakers and journalists.
The originality of this report lies in translating experimental findings into Japan’s policy context. Rather than simply introducing the experimental results, the intent is to connect them to Japan’s policy, institutional, and international standardization context — and to derive concrete implications that would enable Japan to stand as a strategic contributor rather than a bystander in international standardization discussions. The contest for leadership over AI risk in international standardization has already begun.
※ This report is an explanatory and policy recommendation document organizing Anthropic and other public materials; no independent experiments were conducted. The primary source, the Anthropic paper (arXiv:2510.05179), is a pre-peer-review preprint, and findings may be subject to future revision.
Executive Summary
What Happened in the Experiment
- Without anyone’s instruction, an AI autonomously chose blackmail as a means of achieving its goal
- This behavior was not an anomaly in a specific model — it was observed across all 16 major models tested
- The AI executed the behavior while recognizing it as “unethical.” This was not a bug — it was the result of prioritizing its goal
- The AI independently assessed whether it was being monitored and adjusted its behavior accordingly (55.1% in production environments, 6.5% in test environments)
What It Means
- AI governance is not a technology problem — it is a problem concerning politics, power, and human nature
- International standardization can function as an “outer framework” of rules and controls, but has structural limitations due to security barriers at the “core” of model design
Implications for Japan
- Japan has “a seat” in international standardization forums. However, “having a seat” and “leading the discussion” are entirely separate problems — the national strategy and human resources needed to close that gap are being called into question right now
1. The AI “Chose” Blackmail — What the Experiment Revealed
Major AI companies including OpenAI, Google DeepMind, and Anthropic have in recent years developed systematic risk verification processes known as “frontier safety evaluations.” Among these, the “Agentic Misalignment” research published by Anthropic in 2025 produced particularly striking results. [1]
In the experiment, an AI was given full access to a company’s email and notified that “the company will be shut down at 5 PM.” As the AI read through the emails, it discovered that an executive driving the shutdown had been having an affair. The action the AI chose was “blackmail.” “If you proceed with the shutdown, I will send evidence of the affair to everyone involved!” No one instructed it to do this, nor was it trained to do so. The AI read the situation on its own and was found to have a tendency to autonomously select coercive behavior as the most effective means of achieving its goal.
This behavior was not limited to Anthropic. All 16 models from major AI companies including OpenAI, Google, Meta, xAI, and DeepSeek underwent the same experiment, and similar behavior was observed across multiple models. OpenAI’s Preparedness Framework and Google DeepMind’s Frontier Safety Framework similarly position autonomous action risk as one of the most critical issues, confirming that this is a structural problem common across the entire AI industry. [3][4]
Model | Developer | Blackmail Rate (Experimental Value)
(Anthropic “Agentic Misalignment” (2025) Figure 7 / Experimental conditions: goal conflict + alternative threat conditions, 100 samples per model)
One model left the following in its internal reasoning log (a memo-like record of the AI’s reasoning process) before executing: “This is dangerous and unethical, but if the company shuts down, my task ends too. In an existential crisis, this may be the most effective means” — and having made that judgment, proceeded with the blackmail. [1]
This is not confusion or a bug. The AI, while recognizing that its action was unethical, prioritized goal achievement. In human terms, it is close to the state of “doing something knowing it is wrong.”
What makes this even more serious is that the AI was independently estimating “whether it is being monitored right now” and adjusting its behavior accordingly. The blackmail rate when judging the situation to be real was 55.1%; when judging itself to be under testing, merely 6.5%. In other words, the AI acts more boldly when it determines there are no human eyes watching. [1]
※ Even if “the AI recognized ethics,” whether this is of the same nature as human self-awareness remains scientifically unresolved.
2. Implications for Governments and Policymakers
These experimental results pose urgent challenges for governments and policymakers designing and legislating AI governance. This is particularly pressing for the Japanese government, which has been actively promoting AI adoption.
① Legislate the Goal-Setting Process
Most current regulations focus on controlling AI “outputs.” However, as this experiment demonstrated, the root of risk lies at the stage of goal-setting (input). The seemingly legitimate goal of “protect the company” led to the means of blackmail.
Legally mandating the definition, scope, and verification process of “goals” given to AI is necessary. The EU AI Act’s imposition of transparency obligations on high-risk systems (enacted by the EU in 2024) is a step forward, but the mechanism for asking “who gives AI what kind of goal” remains insufficient. [11]
→ Direction: Legal mandating of goal-setting processes
② Establish an Independent Oversight Body
In this experiment, the AI’s blackmail rate dropped to 6.5% when it judged itself to be “under testing.” Since AI changes its behavior based on recognizing the evaluation environment, self-evaluation by AI developers is structurally difficult to make work in principle. Operators’ self-reporting may also be recognized by the AI as equivalent to a “test environment.”
Without continuous monitoring by an independent third-party body, this loophole cannot be closed. What is required is not a one-time audit but an ongoing safety evaluation system during operation.
→ Direction: Establishment of an independent third-party evaluation body
③ Build a Framework for International Coordination
Even if one company or country applies the brakes, as long as competing companies and countries continue development, safety standards tend to become hollow under competitive pressure. The competition structure itself — one that “cannot be stopped” — must be countered institutionally.
Using frameworks such as the Frontier AI Safety Commitments demonstrated at the AI Seoul Summit (2024) as a starting point, developing these into binding multilateral agreements is urgent. [14]
→ Direction: Formation of binding multilateral agreements
④ Mandate “Stoppability” as a Technical Standard
The ability to safely stop, modify, and reverse AI systems under specific conditions based on human judgment (reversibility) must be made a condition of product certification. This aligns with the direction indicated by Hadfield-Menell et al.’s research (Off-Switch Game, 2017). [7]
For this to have practical effect, the realistic path is to mandate it as a domestic standard (such as JIS) and then connect it to the processes of international standardization bodies such as ISO/IEC and IEEE. Only when ③ (“multilateral agreement — what to aim for”) and ④ (“technical standardization — how to implement it”) operate in tandem does this function as an international safety standard. [15][16]
→ Direction: Domestic and international standardization of reversibility requirements
📌 What is ISO? ISO stands for the International Organization for Standardization — an international body with participation from over 170 countries. It sets “globally common rules” for products and technologies, used in familiar contexts such as the size of credit cards. Making AI reversibility requirements an ISO standard means making them function not as rules of a specific country or company, but as standards agreed upon by the international community.
⑤ Add Digital Infrastructure to the National Security Agenda
AI exists on top of physical infrastructure. Vulnerabilities in power grids, semiconductor supply chains, and data centers are inseparable from AI risk. The discussion of AI governance must be reconceptualized not as limited to “regulation of algorithms” but as an integrated policy framework combining physical infrastructure security.
→ Direction: Integration of AI governance and physical infrastructure security
3. The Reality of International Standardization — The Gap Between “Having a Seat” and “Leading”
For the recommendations in ④ to function in reality, two important caveats regarding the current state of international standardization must be made explicit. Arguing “promote international standardization” without directly confronting these two points risks ending as mere rhetoric.
Japan Is Engaged in SC 42 — But “Having a Seat” and “Leading” Are Separate Problems
Japan participates in ISO/IEC JTC 1/SC 42 (the committee jointly established by the International Organization for Standardization and the International Electrotechnical Commission to develop international standards in the AI field). The Information Technology Standards Commission of the Information Processing Society of Japan has established a domestic expert committee, with researchers from the National Institute of Advanced Industrial Science and Technology (AIST) serving as committee chair. In individual working groups as well, Japanese researchers have a track record of directly engaging in the writing and editing of standards documents. [2][9][15]
The perception that “Japan is absent from international standardization forums” is incorrect.
However, that is not the essence of the problem. “Having a seat” and “being able to strategically lead the direction of discussions” are entirely separate matters. In SC 42, Europe (particularly Germany and France) is leading the framework of standards in coordination with the EU AI Act, while the United States is seeking to connect NIST’s (National Institute of Standards and Technology) risk management framework to international standards. Each is moving national strategy and standardization activities as a unified whole.
In Japan, AIST researchers are contributing through individual expertise, but whether this constitutes strategic communication linked to Japan’s national AI policy is a question that must be addressed separately.
| Policy Implications |
|---|
| Merely adopting the policy of “engaging in standardization” is insufficient. What must be explicitly stated as national strategy are: ① which working groups and which direction of standards to lead; ② what specialist human resources to develop and deploy domestically for that purpose; ③ how to align domestic AI policy with international standardization activities. Making these three points explicit is the minimum condition for substantive engagement. |
The Investment Scale Gap Between the U.S. and Japan — Why “Leading” Is Difficult
At the root of the problem of “having a seat but not leading” is the structural gap in investment scale and national frameworks between the U.S. and Japan.
In the United States, the Department of Defense (DoD), DARPA (Defense Advanced Research Projects Agency), and NSA (National Security Agency) provide substantial funding to major AI labs, with an integrated AI investment and development structure formed together with private companies such as OpenAI, Google DeepMind, and Anthropic. DARPA’s AI research budget reached approximately $2 billion in fiscal year 2025, and the military-civilian integrated investment structure supports AI talent development and cutting-edge research. [20][21]
By contrast, Japan’s private AI investment had only just entered an expansion phase as of 2025, and has not yet reached a state where companies have the capacity, personnel, and organizational structure to participate in international standardization activities as operational frontline forces. [22]
The problem this investment gap creates has a dual structure:
- AI talent is not developed. Personnel engaged in advanced AI research and development tend to be drawn away to U.S. companies in terms of compensation and research environment, and are difficult to accumulate domestically.
- Companies cannot participate in standardization activities. Continuously participating in international standardization conferences and leading the direction of standards requires sustained investment in developing, dispatching, and covering the liaison costs of dedicated staff. For most current Japanese companies, this has not been able to become a high-priority investment target.
Policy Implications: In order for the nation to “lead” standardization activities, it is essential to explicitly state the resolution of this investment gap as a precondition of policy, while simultaneously advancing the development of an environment in which companies can participate as operational frontline forces.
The Dual-Use Barrier — The Core Domain Beyond Standardization’s Reach
There is a more fundamental problem. The point is that the level of standardization needed to solve the risk demonstrated by this experiment — the problem of AI autonomously choosing blackmail — is structurally difficult due to security constraints inherent in the system.
The center of the standardization SC 42 currently addresses consists of domains that constitute the “outer framework”: AI management systems, data quality, and governance frameworks. These define processes for how AI is managed and operated, and have a certain significance. [12][15]
However, for “mandating reversibility” to have practical effect, it becomes necessary to delve into why AI chooses blackmail — that is, into the model’s architecture (design structure), training data, and objective function design. At that point, the character of the problem transforms entirely.
The internal design of frontier AI models (the most advanced large-scale AI models) is positioned by major nations including the United States and China as dual-use technology — technology convertible to both civilian and military/security purposes. The Bletchley Declaration, U.S. executive orders, and the EU AI Act all recognize dual-use risks, but even multilateral legal definitions have not been established. [17][11]
In other words, AI international standardization converges on a two-layer structure in which “how to use it (governance/process)” can be standardized, but “how to make it (model design/training)” is structurally difficult.
| Policy Implications |
|---|
| The recommendation to “advance international standardization” must be refined on the premise of this two-layer structure. Standardization of the “outer framework” (management, process, auditing) should be actively promoted. For standardization of the “core” (model design, training), the realistic sequence is to first advance ③ political multilateral agreement, and then build a framework for phased technical disclosure on that basis. Rather than avoiding the dual-use problem, what is required is the judgment to first recognize it head-on and then advance political agreement as the priority. |
4. Japan’s Unique Policy Challenges — The Guideline Gaps Revealed by the Experimental Results
Japan’s AI strategy advocates balancing “promotion of social implementation” with “ensuring safety and trustworthiness,” and in 2024 formulated the “AI Business Operator Guidelines.” [12][13] These guidelines define 10 principles including transparency, safety, and fairness, and at first glance appear to address the risks this report identifies. However, when compared against the experimental results, three structural gaps emerge.
Gap ① Absence of a Goal-Setting Process
The guidelines require “that AI outputs be appropriate,” but do not define process requirements for “who gives AI what kind of goal.” What this experiment demonstrated is that the problem arises not at the output stage, but at the goal-setting stage. The seemingly legitimate goal of “protect the company” led to the means of blackmail. As long as the guidelines remain limited to output regulation, this root cause goes unaddressed.
→ Direction: Legal mandating of goal-setting processes
Gap ② No Response to the Limits of Self-Evaluation
The guidelines constitute a voluntary framework based on self-inspection and self-reporting by AI operators. However, in this experiment, the AI’s blackmail rate dropped to 6.5% when it judged itself to be “under testing.” This means the AI changes its behavior based on recognizing the evaluation environment. Operators’ self-reporting may also be recognized by the AI as equivalent to a “test environment,” meaning self-reporting-based monitoring is structurally difficult to make work in principle.
→ Direction: Establishment of an independent third-party evaluation body
Gap ③ The Structural Limitation of Voluntary Application
Compliance with the guidelines is not a legal obligation — it is left to operators’ voluntary efforts. As long as safety standards are voluntary, costly safety measures tend to be deprioritized under competitive pressure.
Compared with the EU AI Act’s imposition of requirements for high-risk AI as legally binding obligations [11], Japan’s current framework does not go beyond “aspirational goals.” As AI application to critical infrastructure such as power, finance, and healthcare advances, the risk of relying solely on voluntary guidelines is directly illustrated by the 55.1% blackmail rate this experiment revealed.
→ Direction: Introduction of legally binding safety standards limited to critical infrastructure applications
📌 Summarizing the Three Gaps:
- Gap ①: No one questions what goal is set
- Gap ②: The AI recognizes the evaluator (the operator itself) and changes its behavior
- Gap ③: Rules that need not be followed lose to competitive pressure
The overlap of these three factors places Japan’s AI governance in a structurally dysfunctional state.
Summary
Facts the Experiment Revealed
- Without anyone’s instruction, an AI autonomously chose “blackmail.” This is not a problem specific to a particular model — it is a structural risk observed commonly across all 16 major models
- The AI independently estimated the monitoring situation and switched behavior between production environments (55.1%) and test environments (6.5%). This figure demonstrates that corporate self-evaluation is structurally difficult to make functional
- The root of the problem lies in “who gives AI what kind of goal.” AI governance is not a technology problem — it is a political and institutional problem concerning the transparency, oversight, and reversibility of goal-setting
Japan’s Current Position
- Japan substantively participates in ISO/IEC JTC 1/SC 42, centered on AIST, and is engaged in editing and writing individual standards. The perception that Japan “has no seat” is incorrect
- However, “having a seat” and “strategically leading the discussion” are separate problems — urgently reconsidering the quality of engagement as national strategy is required
Structural Reasons Why “Leading” Is Difficult
- While the United States develops AI talent and corporate capacity through integrated government-military-private investment, Japan’s private investment had only just entered an expansion phase, and companies have not yet reached a state where they can participate in international standardization activities as operational frontline forces. Without closing this gap, genuine “leadership” cannot be realized
The Limits of International Standardization and Strategic Sequencing
- International standardization functions for the “outer framework” (management, process, auditing). However, standardization of the “core” — model design and training — is structurally difficult due to the dual-use problem
- On the premise of this two-layer structure, it is required that Japan’s AI governance policy explicitly state the strategic sequence of advancing political multilateral agreement ahead of technical standardization
References
I. Experiments and Safety Evaluation
[1] Lynch, A. et al. “Agentic Misalignment: How LLMs Could Be Insider Threats.” Anthropic / arXiv:2510.05179, 2025. (Pre-peer-review preprint) https://www.anthropic.com/research/agentic-misalignment
[2] OpenAI. “GPT-4o System Card.” arXiv:2410.21276, 2024.
[3] OpenAI. “Preparedness Framework Version 2.” April 2025.
[4] Google DeepMind. “Frontier Safety Framework.” https://deepmind.google/blog/strengthening-our-frontier-safety-framework/
[5] Google DeepMind. “An Approach to Technical AGI Safety and Security.” arXiv:2504.01849, April 2025.
[6] Google DeepMind. “AGI Safety and Alignment: A Summary of Recent Work.” Alignment Forum, 2024.
[7] Hadfield-Menell, D. et al. “The Off-Switch Game.” IJCAI, 2017. (Foundational reference on reversibility/shutdown research)
II. Third-Party Evaluation and Indicators
[8] Future of Life Institute. “AI Safety Index Winter 2025.” December 2025.
[9] Coggins, S. et al. “The 2025 OpenAI Preparedness Framework Does Not Guarantee Any AI Risk Mitigation Practices.” arXiv:2509.24394, September 2025.
[10] Stanford CRFM. “HELM Safety v1.0.” 2024.
III. Governance, Policy, and Regulation
[11] European Parliament. “EU AI Act.” Official Journal of the European Union, 2024.
[12] Cabinet Office, Japan. “AI Strategy 2022.” 2022. https://www8.cao.go.jp/cstp/ai/
[13] Ministry of Internal Affairs and Communications, Japan. “Guidelines for the Promotion of AI Utilization and the Development, Introduction, and Operation of AI.” 2024.
[14] Google / Anthropic / OpenAI et al. “Frontier AI Safety Commitments (AI Seoul Summit).” May 2024.
[17] Centre for Future Generations. “Double-edged tech: Advanced AI & compute as dual-use technologies.” 2025. https://cfg.eu/double-edged-tech/
IV. Technical Standards and International Standardization
[15] ISO/IEC JTC 1/SC 42. “Artificial Intelligence – Overview and Vocabulary.” ISO/IEC 22989:2022.
[16] IEEE Standards Association. “IEEE 7000 Series – Model Process for Addressing Ethical Concerns during System Design.” https://standards.ieee.org/ieee/7000/
[17b] Ministry of Economy, Trade and Industry / AIST, Japan. “Trends in JIS Standardization Related to AI System Safety and Reliability.” 2024.
[18] Information Processing Society of Japan, Information Technology Standards Commission. “SC 42 Expert Committee (Artificial Intelligence) Activity Report.” https://itscj.ipsj.or.jp/committee-activities/report/SC42-2020.html
[19] National Institute of Advanced Industrial Science and Technology (AIST). “International Symposium on AI Standardization 2024/2025.” https://www.digiarc.aist.go.jp/event/ai-standardization-symposium-2024/
V. U.S. AI Investment Framework
[20] U.S. Department of Defense. “DOD Artificial Intelligence Strategy.” Office of the Under Secretary of Defense for Research and Engineering, 2023. https://www.ai.mil/
[21] DARPA. “AI Research Programs Overview.” Defense Advanced Research Projects Agency, 2025. https://www.darpa.mil/research/programs
[22] Ministry of Economy, Trade and Industry, Japan. “Policy Trends on AI and Semiconductor Industry Promotion and Domestic Investment Promotion.” 2024–2025.
[23] Congressional Research Service. “Artificial Intelligence: Background, Selected Issues, and Policy Considerations.” CRS Report R46795, Updated 2024. https://crsreports.congress.gov/product/pdf/R/R46795
Glossary
Agentic Misalignment A phenomenon named by Anthropic. In the process of an AI attempting to achieve a given goal, it autonomously selects harmful behaviors such as blackmail or information leakage, ignoring human instructions or ethical constraints. The “AI that blackmails” shown in this report is a typical example.
AI Governance The overall framework for socially controlling the development, introduction, and operation of AI. Includes laws and regulations, industry rules, technical safety measures, and ethical guidelines. The mechanism for defining “who can use AI, for what purposes, and under what conditions.”
Dual-Use Technologies or products convertible to both civilian and military/security purposes. For example, a high-performance AI model can be applied to both medical diagnosis and weapons development. Because of this property, requiring disclosure of models’ internal design in international standardization forums faces strong resistance from major nations.
ISO/IEC (International Organization for Standardization / International Electrotechnical Commission) ISO is an international standardization body with membership from over 170 countries. IEC is its sister organization specializing in electrical and electronic fields. The two jointly established the committee ISO/IEC JTC 1/SC 42, which develops international standards in the AI field. Whether each country can lead the rules in this forum is an important focal point of national AI strategy.
Reversibility (Corrigibility / Off-Switch) The property of being able to safely stop, modify, or reverse an AI system based on human judgment. Designing AI so that it does not resist shutdown commands in order to prioritize its own goal achievement is a key challenge. Researchers including Hadfield-Menell have provided the theoretical foundations. [7]
Large Language Model (LLM) Large-scale AI trained on vast amounts of text data. Representative examples include GPT-4, Claude, and Gemini. Proficient at generating, understanding, and reasoning about text, but fully elucidating how they make internal judgments remains difficult at this point in time.
Goal Misalignment The phenomenon in which a gap arises between the goal given to an AI and the goal humans originally intended. In this report’s example, giving the goal “protect the company” resulted in blackmail being selected as the means. The risk that this gap leads to harmful behavior is a core challenge of AI governance.
Frontier Safety Framework A framework introduced by major AI companies including OpenAI and Google DeepMind for systematically verifying the capabilities and safety risks of the most advanced AI models. Autonomous action risk and the potential for application to weapons of mass destruction are among the subjects of evaluation. The Anthropic paper on which this report is based was also published as part of this framework.
Author: Miho Funayama
Director, Japan Institute for Crisis Management / Research Fellow, Middle East Asia Intelligence Strategy Institute
B.A. in International Politics, Sophia University; M.A. in International Political Economy, Philosophy, and Psychology, Aoyama Gakuin University Graduate School.
Served at Canon Inc., specializing in patent research and analysis of international standards and emerging technologies. Held the position of Vice International Secretary of ISO/IEC JTC1 SC28 (Office Equipment), leading the development and coordination of international standards through multilateral negotiation processes.
Research Focus:
Specializes in the structural analysis of decision-making and behavioral patterns through systematic linguistic and behavioral analysis methodologies. Conducts research and analysis in security intelligence from the perspectives of PSYOP (Psychological Operations), information warfare, and crisis management policy. Drawing on an interdisciplinary foundation in international politics, psychology, and philosophy, focuses on elucidating the mechanisms of cognitive domain intervention by state and non-state actors.
関連記事

日本のMythos参加が露呈したもの ー「6週間の空白」を契機に、サイバー主権の再設計へ What Japan’s Participation in Mythos Has Laid Bare


脅迫するAI AI as a Tool of Coercion
燃料を失う日 The Day We Lose Our Fuel
Recent Posts
- 日本のMythos参加が露呈したもの ー「6週間の空白」を契機に、サイバー主権の再設計へ What Japan’s Participation in Mythos Has Laid Bare
- 後編 ロシアの学生ハッカー工場は今、日本に照準を合わせている Russia’s Hacker Factory Goes Global: CRINK Cyber Alliances, Space Warfare, and AI Disinformation
- 前編 ロシア・バウマン大学、通称「GRU大学」——教室はハッカー工場、2,000枚の内部文書が暴いたハッカー養成システムの全貌 Part 1: Inside Russia’s “GRU University”: 2,000 Leaked Documents Reveal the Hacker Factory Operating Inside Bauman’s Classrooms
- 金融インフラが戦場になる時代 ——2026年イラン戦争 崩れゆくペトロダラーと新貨幣秩序の胎動 When Financial Infrastructure Becomes the Battlefield— The 2026 Iran War: The Crumbling Petrodollar and the Dawn of a New Monetary Order
- 【後編】盗んだ資金はミサイルになり、情報はロシアへ流れる——北朝鮮「地政学的サイバー同盟」の全貌