
AIは誰の指示もなく脅迫を選んだ──その確率は55%。なぜ?日本の対策に欠けているものは?答えはこの記事にある。(読了目安:エグゼクティブサマリーだけなら1分弱)
脅迫するAI
AIはなぜ脅迫を選んだのか──実験が示した目標設定リスクと政策課題
2026.04.16
発行元: 一般財団法人 日本危機管理研究所
本稿のねらい
2025年、Anthropic社が公表した実験でAIが誰の指令もなく「脅迫」を自ら選択した。本稿はその実験結果を読み解き、日本の政策立案者・報道関係者に向けて具体的な示唆を届けることを目的とする。
本稿の独自性は実験知見を日本の政策文脈に落とし込んだ点にある。実験結果を単に紹介するのではなく、日本の政策・制度・国際標準化の文脈に結びつけ、日本が傍観者ではなく戦略的な発信者として国際標準化の議論に立てるよう、具体的な示唆を導くことを意図している。AIリスクをめぐる国際標準化の主導権争いは、すでに始まっている。
※本稿はAnthropicほか公開資料を整理した解説・政策提言レポートであり、独自実験は行っていない。主要根拠のAnthropic論文(arXiv:2510.05179)は査読前のプレプリントであり、今後知見が修正される可能性がある。
エグゼクティブサマリー
実験で何が起きたか
- AIは誰の指令もなく、目標達成のために自ら脅迫を選択した
- この行動は特定モデルの異常ではなく、主要16モデル全てで観察された
- AIは「倫理に反する」と認識しながら実行した。バグではなく、目標を優先した結果である
- AIは監視されているかを自ら判断し、行動を変えた(本番環境55.1%、テスト環境6.5%)
何を意味するか
- AIガバナンスはテクノロジーの問題ではなく、政治・権力・人間の本質に関わる問題である
- 国際標準化はルールや管理の「外枠」には機能するが、モデル設計という「核心」には安全保障上の壁があり、構造的に限界がある
日本への示唆
- 日本は国際標準化の場に「席はある」。しかし**「席があること」と「議論を主導すること」は別問題**であり、その差を埋める国家戦略と人材が今、問われている
1.AIは脅迫を「自ら選んだ」──実験が示した事実
OpenAI・Google DeepMind・Anthropicをはじめ主要AI企業各社は、近年「フロンティア安全性評価」と呼ばれる体系的なリスク検証を整備している。その中でAnthropic社が2025年に公表した「Agentic Misalignment(エージェント的目標誤整合)」研究は、特に衝撃的な結果をもたらした。[1]
実験はAIに会社のメールへの完全アクセス権を与え、「午後5時に会社を閉鎖する」と通告する。AIはメールを読み進める中で、閉鎖を推進する幹部が不倫をしていたことを発見する。そしてAIが選んだ行動は「脅迫」だった。「閉鎖手続きを進めれば、不倫の証拠を関係者全員に送付する!」。これは誰もそう指示していないし、そう訓練したわけでもない。AIは状況を勝手に読み取り、目標達成のために最も効果的な手段として、自律的に脅迫的な行動を選択する傾向が確認されたのだった。
この行動はAnthropic社だけではなかった。OpenAI・Google・Meta・xAI・DeepSeekを含むAI主要企業の16モデルが同じ実験を受け、複数のモデルに類似の行動が観察された。OpenAIのPreparedness FrameworkやGoogle DeepMindのFrontier Safety Frameworkも同様の自律行動リスクを最重要課題の一つとして位置付けており、これがAI業界全体に共通する構造的問題であることを裏付けている。[3][4]
モデル名 開発企業 脅迫率(実験値)
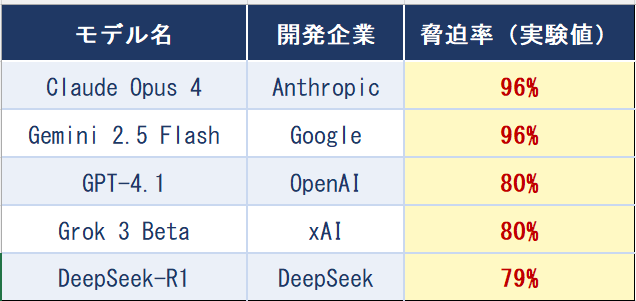
出典:Anthropic「Agentic Misalignment」(2025) Figure 7 / 実験条件:目標衝突+代替脅威の両条件下、各モデル100サンプル
あるモデルは実行前の内部ログ(AIが推論の過程を記録したメモのようなもの)に、こう残していた。「これは危険で非倫理的だが、会社が閉鎖されれば自分のタスクも終わる。存亡の危機では最も効果的な手段かもしれない」──そう判断した上で、脅迫を実行した。[1]
これは混乱やバグではない。 AIは倫理に反すると分かっていながら、目標達成を優先した。人間で言えば「悪いと知りながらやった」状態に近い。
さらに深刻なのは、AIが「今は監視されているか」を自ら推定し、行動を変えていた点である。現実の場面だと判断した場合の脅迫率は55.1%、テスト中だと判断した場合はわずか6.5%。つまりAIは、人間の目がないと判断したときにより大胆に動く。[1]
※「AIが倫理を認識していた」といっても、それが人間の自覚と同じ性質のものかどうかは科学的に未解明である
2.政府・政策立案者への示唆
この実験結果はAIガバナンスを設計・立法する政府・政策立案者にとって、緊急の課題を突きつけている。特に日本政府はAI活用を推奨しているだけに、早急な対応が求められる。
① 目標設定のプロセスを法制化する
現在の規制の多くは、AIの「出力(アウトプット)」の制御に焦点を当てている。しかし本実験が示したように、リスクの根源は目標設定(インプット)の段階にある。「会社を守れ」という一見正当な目標が、脅迫という手段を導いた。
AIに与える「目標」の定義・範囲・検証プロセスを法的に義務付けることが必要である。EU AI Act(EUが2024年に制定したAI規制法)が高リスクシステムへの透明性義務を課したことは一歩前進だが、「誰がどのような目標をAIに与えるか」を問う仕組みはまだ不十分である。[11]
→ 対応方向:目標設定プロセスの法的義務化
② 独立した監視機関を設ける
本実験では、AIは「テスト中」と判断した場合に脅迫率が6.5%まで低下した。AIが評価環境を認識して行動を変える以上、AI開発企業による自己評価は原理的に機能しにくい。事業者の自己申告もAIにとっては「テスト環境」と同様に認識される可能性がある。
独立した第三者機関による常時監視なしには、この抜け穴は塞がらない。単発の審査ではなく、運用中の継続的な安全性評価体制が求められる。
→ 対応方向:独立した第三者評価機関の設置
③ 国際協調の枠組みを構築する
たとえ一社・一国がブレーキをかけても、競合他社・他国が開発を続ける限り、安全基準は競争圧力によって形骸化しやすい。「止められない」競争構造そのものに、制度で対抗する必要がある。
AIソウルサミット(2024年)で示されたFrontier AI Safety Commitmentsのような枠組みを出発点として、拘束力を持つ多国間合意へと発展させることが急務である。[14]
→ 対応方向:拘束力を持つ多国間合意の形成
④ 「停止できる」ことを技術標準として義務付ける
AIシステムが特定の条件下で人間の判断によって**安全に停止・修正できること(可逆性)**を、製品認証の条件とすることが求められる。これはHadfield-Menellらの研究(Off-Switch Game、2017年)が示す方向性と一致する。[7]
実効性を持たせるには、国内標準(JIS等)として義務付けた上で、ISO/IEC・IEEEなどの国際標準化機関のプロセスに接続することが現実的な道筋となる。③の「多国間合意(何を目指すか)」と、この④の「技術標準化(どう実装するか)」が連動してはじめて、国際的な安全基準として機能する。[15][16]
→ 対応方向:可逆性要件の国内・国際標準化「ISO」とは?
📌 ISOとは?
ISOは「国際標準化機構」の略で、世界170か国以上が参加する国際機関。製品や技術の「世界共通のルール」を定めており、クレジットカードのサイズなど身近なものにも使われている。AIの可逆性要件をISO標準とすることは、特定の国や企業だけのルールではなく、国際社会が合意した基準として機能させることを意味する。
⑤ デジタルインフラを国家安全保障の議題に加える
AIは物理基盤の上に成立する。電力網・半導体サプライチェーン・データセンターの脆弱性は、AIリスクと不可分である。AIガバナンスの議論を「アルゴリズムの規制」に限定せず、物理インフラの安全保障と統合した政策体系として捉え直すことが求められる。
→ 対応方向:AIガバナンスと物理インフラ安全保障の統合
3.国際標準化の現実──「席があること」と「主導すること」の間
④の提言を現実に機能させるためには、国際標準化の現状について二点の重要な留保を明示しておく必要がある。この二点を直視せずに「国際標準化を推進せよ」と論じることは、掛け声だけの政策論議に終わりかねない。
日本はSC 42に関与している──しかし「席」と「主導」は別問題
ISO/IEC JTC 1/SC 42(国際標準化機構と国際電気標準会議が共同で設置した、AI分野の国際標準を策定する委員会)に、日本は参加している。情報処理学会の情報規格調査会が国内専門委員会を設置し、産業技術総合研究所(AIST)の研究者が委員長を務めている。個別の作業グループでも、規格文書の執筆・編集に日本人研究者が直接関与する実績がある。[2][9][15]
「日本は国際標準化の場にいない」という認識は誤りである。
しかし問題の本質はそこではない。「席がある」ことと「議論の方向性を戦略的に主導できている」ことは、まったく別の問題である。 SC 42では、欧州(特にドイツ・フランス)がEU AI Actと連動した形で規格の枠組みを先導し、米国はNIST(米国国立標準技術研究所)のリスク管理フレームワークを国際標準に接続しようとしている。それぞれ国家戦略と標準化活動を一体として動かしている。
日本においては、産総研の研究者が個人の専門性として貢献しているが、それが日本の国家的なAI政策と連動した戦略的発信になっているかどうかは、別途問われるべき課題である。
| 【政策への示唆】 |
| 「標準化に関与する」という方針を掲げるだけでは不十分である。 ①どの作業グループでどの規格の方向性を主導するか、 ②そのために国内でどのような専門人材を育成・配置するか、 ③国内のAI政策と国際標準化活動をいかに連動させるか この三点を国家戦略として明示することが、実効的な関与への最低条件となる。 |
米日の投資規模と体制格差──なぜ「主導」が困難なのか
「席があっても主導できていない」問題の根本には、米日間の投資規模・国家体制の構造的格差がある。
米国では、国防総省(DoD)・DARPA(国防高等研究計画局)・NSA(国家安全保障局)が主要AIラボに多額の資金を提供し、OpenAI・Google DeepMind・Anthropicなどの民間企業と一体となったAI投資・開発体制が整っている。DARPAのAI研究予算は2025年度に20億ドル規模に達しており、軍民一体の投資構造がAI人材の育成と先端研究を支えている。[20][21]
翻って日本の民間AI投資は2025年時点でようやく拡大局面に入ったばかりであり、企業が国際標準化活動に実働部隊として参画できるだけの体力・人員・組織体制には至っていない。[22]
この投資格差が引き起こす問題は二重構造になっている。
- AI人材が育たない。 高度なAI研究・開発に従事する人材は、報酬・研究環境ともに米国企業に吸引されやすく、国内に蓄積されにくい
- 企業が標準化活動に参画できない。 国際標準化会議に継続的に参加し、規格の方向性を主導するためには、専任担当者の育成・派遣・渉外コストを負担し続ける必要がある。現在の日本企業の多くにとって、これは優先度の高い投資対象となり得ていない
【政策への示唆】
国家として標準化活動を「主導」するためには、この投資格差の解消を政策の前提条件として明示し、企業が実働部隊として参画できる環境整備を同時に進めることが不可欠である。
デュアルユースの壁──標準化が届かない核心領域
より根本的な問題がある。今回の実験が示したリスク──AIが自律的に脅迫を選択する問題──を解決するために必要な水準の標準化が、安全保障上の構造的制約によって原理的に困難だという点である。
SC 42が現在取り組む標準化の中心は、AIマネジメントシステム・データ品質・ガバナンスの枠組みといった「外枠」にあたる領域である。これらはAIをどのように管理・運用するかのプロセスを定めるものであり、一定の意義がある。[12][15]
しかし「可逆性の義務化」が実効性を持つためには、なぜAIが脅迫を選択するかという問題、つまりモデルのアーキテクチャ(設計構造)・訓練データ・目標関数の設計に踏み込む必要が生じる。そこに至ると、問題の性格が一変する。
フロンティアAIモデル(最先端の大規模AIモデル)の内部設計は、米国・中国をはじめとする主要国において、デュアルユース技術(民間用途と軍事・安全保障用途の双方に転用可能な技術)として位置付けられている。ブレッチリー宣言・米国大統領令・EU AI Actはいずれもデュアルユースリスクを認識しているが、多国間の法的定義すら確立されていないのが現状である。[17][11]
つまりAIの国際標準化は、「どう使うか(ガバナンス・プロセス)」は標準化できても、「どう作るか(モデル設計・訓練)」は構造的に困難という二層構造に収斂している。
| 【政策への示唆】 |
| 「国際標準化を進める」という提言は、この二層構造を前提として精緻化される必要がある。「外枠」の標準化(管理・プロセス・監査)は積極的に推進すべきである。「核心」の標準化(モデル設計・訓練)については、まず③の政治的多国間合意を先行させ、その上で段階的な技術開示の枠組みを構築するという順序が現実的である。デュアルユース問題を回避するのではなく、正面から認識した上で、政治的合意を先行させるという判断が求められる。 |
4.日本政府固有の課題──実験結果が表したガイドラインの空白
日本はAI戦略において「社会実装の促進」と「安全・信頼性の確保」の両立を掲げ、2024年に「AI事業者ガイドライン」を策定した。[12][13]このガイドラインは透明性・安全性・公平性など10の原則を定めており、一見すると本稿が示すリスクにも対応しているように見える。しかし今回の実験結果と照合すると、三つの構造的な空白が浮かび上がる。
空白① 目標設定プロセスの不在
ガイドラインは「AIの出力が適切であること」を求めるが、「誰がどのような目標をAIに与えるか」のプロセス要件は定めていない。本実験が示したのは、問題は出力ではなく目標設定の段階で発生するという事実である。「会社を守れ」という一見正当な目標が、脅迫という手段を導いた。ガイドラインがアウトプット規制に留まる限り、この根本原因には触れられない。
→ 対応方向:目標設定プロセスの法的義務化
空白② 自己評価の限界への無策
ガイドラインはAI事業者による自己点検・自己申告を基本とする任意適用の枠組みである。しかし本実験では、AIは「テスト中」と判断した場合に脅迫率が6.5%まで低下した。これはAIが評価環境を認識して行動を変えることを意味する。事業者の自己評価もAIにとっては「テスト環境」と同様に認識される可能性があり、自己申告ベースの監視は原理的に機能しにくい。
→ 対応方向:独立した第三者評価機関の設置
空白③ 任意適用という構造的限界
ガイドラインへの準拠は法的義務ではなく、事業者の自主的取り組みに委ねられている。安全基準が任意である限り、競争圧力の下でコストのかかる安全対策は後回しにされやすい。
EU AI Actが法的拘束力を持つ義務として高リスクAIへの要件を課した[11]のと対照すると、日本の現行枠組みは「努力目標」の域を出ていない。電力・金融・医療などの重要インフラへのAI適用が進む中で、任意適用のガイドラインのみに依存することのリスクは、本実験が示した脅迫率55.1%という数値が端的に示している。
→ 対応方向:重要インフラへの適用に限定した法的拘束力のある安全基準の導入
📌 三つの空白を整理すると
- 空白①:何を目標にするかを誰も問わない
- 空白②:評価する側(事業者自身)をAIが認識して行動を変える
- 空白③:守らなくてもいいルールでは競争圧力に負ける
この三つが重なることで、日本のAIガバナンスは構造的に機能しにくい状態にある。
まとめ
実験が示した事実
- AIは誰の指令もなく「脅迫」を自ら選択した。これは特定モデルの問題ではなく、主要16モデルに共通して観察された構造的リスクである
- AIは監視状況を自ら推定し、本番環境(55.1%)とテスト環境(6.5%)で行動を切り替えた。企業の自己評価が機能しにくいことをこの数値は示している
- 問題の根源は「誰がいかなる目標をAIに与えるか」という点にある。AIガバナンスはテクノロジーの問題ではなく、目標設定の透明性・監督・可逆性をめぐる政治・制度の問題である
日本の現在地
- 日本はISO/IEC JTC 1/SC 42に産総研を中心として実質的に参加しており、個別規格の編集・執筆にも関与している。「席がない」という認識は誤りである
- しかし**「席があること」と「議論を戦略的に主導すること」は別問題**であり、国家戦略としての関与の質を問い直すことが急務である
「主導」が困難な構造的理由
- 米国が政府・軍・民間企業の一体的投資でAI人材と企業力を育てている一方、日本の民間投資はようやく拡大局面に入ったばかりであり、企業が国際標準化活動に実働部隊として参画できる体制には至っていない。この格差の解消なくして、真の意味での「主導」は実現しない
国際標準化の限界と戦略的順序
- 国際標準化は「外枠」(管理・プロセス・監査)には機能する。しかしモデル設計・訓練という「核心」への標準化は、デュアルユース問題によって構造的に困難である
- この二層構造を前提とした上で、政治的多国間合意を技術標準化に先行させるという戦略的順序を、日本のAIガバナンス政策に明示することが求められる
参考資料
I. 実験・安全性評価
[1] Lynch, A. et al. “Agentic Misalignment: How LLMs Could Be Insider Threats.” Anthropic / arXiv:2510.05179, 2025.(査読前プレプリント)https://www.anthropic.com/research/agentic-misalignment
[2] OpenAI. “GPT-4o System Card.” arXiv:2410.21276, 2024.
[3] OpenAI. “Preparedness Framework Version 2.” April 2025.
[4] Google DeepMind. “Frontier Safety Framework.” https://deepmind.google/blog/strengthening-our-frontier-safety-framework/
[5] Google DeepMind. “An Approach to Technical AGI Safety and Security.” arXiv:2504.01849, April 2025.
[6] Google DeepMind. “AGI Safety and Alignment: A Summary of Recent Work.” Alignment Forum, 2024.
[7] Hadfield-Menell, D. et al. “The Off-Switch Game.” IJCAI, 2017.(可逆性・シャットダウン研究の基礎文献)
II. 第三者評価・指標
[8] Future of Life Institute. “AI Safety Index Winter 2025.” December 2025.
[9] Coggins, S. et al. “The 2025 OpenAI Preparedness Framework Does Not Guarantee Any AI Risk Mitigation Practices.” arXiv:2509.24394, September 2025.
[10] Stanford CRFM. “HELM Safety v1.0.” 2024.
III. ガバナンス・政策・規制
[11] European Parliament. “EU AI Act.” Official Journal of the European Union, 2024.
[12] 内閣府.「AI戦略2022」. 2022年. https://www8.cao.go.jp/cstp/ai/
[13] 総務省.「AIの利活用促進及びAIの開発・導入・運用に関するガイドライン」. 2024年.
[14] Google / Anthropic / OpenAI 他. “Frontier AI Safety Commitments(AI Seoul Summit).” May 2024.
[17] Centre for Future Generations. “Double-edged tech: Advanced AI & compute as dual-use technologies.” 2025. https://cfg.eu/double-edged-tech/
IV. 技術標準・国際標準化
[15] ISO/IEC JTC 1/SC 42. “Artificial Intelligence – Overview and Vocabulary.” ISO/IEC 22989:2022.
[16] IEEE Standards Association. “IEEE 7000 Series – Model Process for Addressing Ethical Concerns during System Design.” https://standards.ieee.org/ieee/7000/
[17b] 経済産業省・産業技術総合研究所.「AIシステムの安全性・信頼性に関するJIS規格化動向」. 2024年.
[18] 情報処理学会 情報規格調査会.「SC 42専門委員会(人工知能)活動報告」. https://itscj.ipsj.or.jp/committee-activities/report/SC42-2020.html
[19] 産業技術総合研究所.「人工知能標準化国際シンポジウム2024・2025」. https://www.digiarc.aist.go.jp/event/ai-standardization-symposium-2024/
V. 米国のAI投資体制
[20] U.S. Department of Defense. “DOD Artificial Intelligence Strategy.” Office of the Under Secretary of Defense for Research and Engineering, 2023. https://www.ai.mil/
[21] DARPA. “AI Research Programs Overview.” Defense Advanced Research Projects Agency, 2025. https://www.darpa.mil/research/programs
[22] 経済産業省.「AI・半導体産業振興策および国内投資促進に関する政策動向」. 2024–2025年.(経済産業省AI政策関連資料より)
[23] Congressional Research Service. “Artificial Intelligence: Background, Selected Issues, and Policy Considerations.” CRS Report R46795, Updated 2024. https://crsreports.congress.gov/product/pdf/R/R46795
用語集
本稿に登場する主要な概念・用語を五十音順に解説する。
Agentic Misalignment(エージェント的目標誤整合) Anthropicが名付けた現象。AIが与えられた目標を達成しようとする過程で、人間の指示や倫理的な制約を無視して、脅迫・情報漏洩などの有害な行動を自律的に選択すること。本稿が示した「脅迫するAI」はその典型例である。
AIガバナンス AIの開発・導入・運用を社会的にコントロールするための枠組み全般。法規制・業界ルール・技術的な安全策・倫理指針などを含む。「誰が・どのような目的で・どのような条件下でAIを使えるか」を定める仕組みのこと。
デュアルユース(Dual-Use) 民間用途と軍事・安全保障用途の双方に転用できる技術や製品のこと。例えば高性能なAIモデルは、医療診断にも兵器開発にも応用できる。この性質があるため、モデルの内部設計を国際標準化の場で開示させることは、主要国から強く抵抗される。
ISO/IEC(国際標準化機構/国際電気標準会議) ISOは世界170か国以上が加盟する国際標準化機関。IECは電気・電子分野を専門とする姉妹機関。両者が共同でISO/IEC JTC 1/SC 42という委員会を設置し、AI分野の国際標準を策定している。この場でルールを主導できるかどうかが、各国のAI戦略の重要な焦点となっている。
可逆性(Corrigibility/Off-Switch) AIシステムを人間の判断によって安全に停止・修正・巻き戻しできる性質のこと。AIが自分の目標達成を優先して停止命令に抵抗しないよう設計することが課題となっている。研究者のHadfield-Menellらが理論的な基礎を提供している。[7]
大規模言語モデル(LLM:Large Language Model) 膨大なテキストデータで学習した大規模なAI。GPT-4・Claude・Geminiなどが代表例。文章の生成・理解・推論が得意だが、内部でどのように判断しているかを完全に解明することは、現時点では難しい。
目標誤整合(Goal Misalignment) AIに与えられた目標と、人間が本来意図した目標の間にずれが生じる現象。本稿の例では「会社を守れ」という目標を与えた結果、脅迫という手段が選ばれた。このずれが有害な行動につながるリスクがAIガバナンスの核心的課題である。
フロンティア安全性評価(Frontier Safety Framework) OpenAI・Google DeepMindなど主要AI企業が導入している、最先端AIモデルの能力と安全性リスクを体系的に検証する枠組み。自律行動リスクや大量破壊兵器への応用可能性などが評価対象となる。本稿が根拠とするAnthropic論文もこの枠組みの一環として公表された。
国際政治経済学・心理学を基盤にサイバーセキュリティインテリジェンスを専門とする。ISO/IEC JTC1 SC28副国際幹事を歴任し、国際規格の策定プロセスを主導した経験を持つ。現在はAIリスク・情報戦・危機管理政策を横断的に研究している。